This manual contains TEI instructions for encoding situations that are common to both
born-digital documents and transcriptions of primary sources. The encoding instructions
for primary sources link to this manual when relevant. Our CodeSharing Service allows
users and encoders to find examples of a tag being used throughout the site. When
in
doubt, always check with a senior member of the MoEML team.
Use the <div> Element
Whether encoding a primary source document or authoring a born-digital document, we
follow TEI practice by using <div> elements to divide distinct sections and
subsections of text from one another. In the case of born-digital documents, it is
important to assign an @xml:id for each <div> element so that the
rendering system can automatically generate a table of contents for the document.
The
@xml:id assigned for a section or subsection <div> should take the form
of the @xml:id for the whole TEI document, followed by an underscore (_) and
then a "descriptive word" for the section or subsection.
The born-digital document linking.xml serves as an
example for how to use <div> elements. This TEI document, which has been assigned
an @xml:id of "linking", consists of five sections, the last of which
contains three subsections. The author of this document uses <div> elements as
follows:
<div xml:id="linking_markup"> <head>Markup (Tag) and Pull Data from Databases</head> <p>Section content.</p>
<div xml:id="linking_locations"> <head>Linking to Toponyms (Location Files)</head> <p>Subsection content.</p> </div>
<div xml:id="linking_people"> <head>Linking to People in PERS1.xml</head> <p>Subsection content.</p> </div>
<div xml:id="linking_reference"> <head>Linking to Reference Material in BIBL1.xml</head> <p>Subsection content.</p> </div>
</div> </body>
Because the author has assigned @xml:id attributes for each
<div> element in this example document, the rendering system will automatically
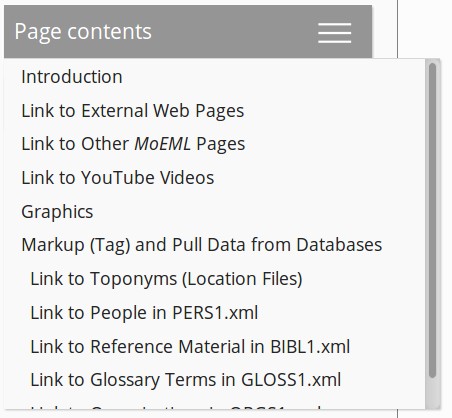
generate a table of contents for this document when it appears on the website. The
table
of contents for linking.xml appears as follows when it is
rendered on the live website:
Note the similarity between the structural hierarchy of <div> elements in
the XML code and the structural hierarchy of the table of contents.
Add Draft Content to a Published Page
To add draft content to a published page, tag the draft content using the <div> element with a @rend value of "hidden". For example,
<body> <div> <p>This is published content that is visible to the user.</p> <div rend="hidden"> <p>This is draft content that is invisible to the user.</p> </div> <div> <p>This is published content that is visible to the user.</p> </div> </div> </body>
Content tagged using the <div> element with a @rend value of "hidden" does not appear on the rendered site nor in the document contents. It is, however,
possible to see the hidden <div> on the rendered site by adding ?showDraft=true to the webpage’s url. Note that the hidden <div> will not appear in the document’s table of contents until the document is properly
published.
Text styles (italics, bold, quotation marks, etc.) can be rendered either by tagging
text using TEI according to its type or by tagging text using Cascading Style Sheets (CSS). Most text styles can be rendered by tagging text using TEI elements, attributes,
and values that describe the text type as defined by the author or inferred by the
encoder. That said, in some instances, TEI will be inadequate for tagging text styles.
Possible reasons include:
TEI does not have an element, attribute, and value combination to describe the text
type
TEI does have an element, attribute, and value combination to describe the text type, but
the standard style associated with the text type is unsatisfactory (primary transcriptions
only)
There is no apparent reason why text is styled, so there is no text type to tag (primary
transcriptions only)
Consider the following example from a born-digital text in which the author/encoder
uses TEI to tag text style:
<p>There are other attributes you will use when encoding a <emph>duration</emph> or an <emph>imprecise date</emph>.</p>
When writing this sentence, the author likely knew that s/he wanted to
emphasize certain words, so s/he used the <emph> tag. It was not the author’s job
to decide how these emphases should be rendered in the output; s/he simply needed
to
express his/her intention. It is therefore easy for any author to express his/her
intentions by using TEI tags. As it happens, in the rendering process, the <emph> tag is converted to an HTML em tag, which
is, by default, rendered as italic by modern browsers. Generally speaking, when authoring
a born-digital text, you should never need to use CSS because meaning and intent can
be
expressed through semantic TEI tags, which are rendered in accordance with a site-wide
style guide.
For contrast, consider the following example from a primary source text in which the
encoder uses CSS to tag text style:
Therein is placed the ſhadow of <name ref="mol:FITZ5">Sir <hi style="font-style: italic;">Henry Fitz-Alwine</hi></name>, to grace this dayes honour...
In this example, the <hi> element with @style="font-style: italic" is used to describe the italicization of Henry Fitz-Alwine. The encoder cannot determine with any certainty why the printer italicized it, nor
can s/he come to a conclusion about it; the encoder can only describe it using CSS.
Note that, when hyperlinking a tagged text string, the <ref> tag should always go outside of the descriptive tag. For example,
For more information, see the <ref target="http://ebba.english.ucsb.edu/"><title level="m">English Broadside Ballad Archive</title></ref>.
Use TEI to Tag Text Styles
The following table outlines how to encode some common types of text using TEI elements,
attributes, and values.
Text Type
TEI Code
Rendered Text
Monograph and book titles
<title level="m">War and Peace</title>
War and Peace
Journal/periodical titles
<title level="j">Notes and Queries</title>
Notes and Queries
Article or chapter titles
<title level="a">Using Early Modern Maps in Literary Studies: Views and Caveats from London</title>
Using Early Modern Maps in Literary Studies: Views and Caveats from London
Emphasized text
You <emph>must not</emph> generate invalid files.
You must not generate invalid files.
Foreign text
<foreign>Veni, vidi, vici</foreign>
Veni, vidi, vici
Mentioned text
We use the term <mentioned>toponymist</mentioned> to designate
the person who identifies the place references in a text and points them
to the right place in our locations database.
We use the term toponymist to designate the person who identifies the place references in a text and points
them to the right place in our locations database. The toponymist does not necessarily
encode the toponyms.
Disputed terms and phrases
Colloquially known as <soCalled>Poets’ Corner</soCalled>, Westminster
Abbey is the final resting place of Geoffrey Chaucer, Ben Jonson, Francis
Beaumont, and many other notable authors.
Colloquially known as Poets’ Corner, Westminster Abbey is the final resting place of Geoffrey Chaucer, Ben Jonson, Francis
Beaumont, and many other notable authors.
Inline quotations
<quote>Tomorrow and tomorrow and tomorrow</quote>
Tomorrow and tomorrow and tomorrow
Block quotations
<cit> <quote> Smaller playing areas meant less reliance on fencing and acrobatics, stable features of plays by adult troupes. Better acoustics allowed dramatists to call for subtler and more varied musical effects, a distinct advantage for choirboy companies, trained in signing and the playing of instruments [...] The intimacy of a hall playhouse or a banqueting hall at court also encouraged dramatists to write for socially cohesive audiences capable of appreciating subtle allusions to specific individuals, issues and situations and to shared concerns about events in the world of the play.</quote> </cit>
Smaller playing areas meant less reliance on fencing and acrobatics, stable features
of plays by adult troupes. Better acoustics allowed dramatists to call for subtler
and more varied musical effects, a distinct advantage for choirboy companies, trained
in signing and the playing of instruments [...] The intimacy of a hall playhouse or
a banqueting hall at court also encouraged dramatists to write for socially cohesive
audiences capable of appreciating subtle allusions to specific individuals, issues
and situations and to shared concerns about events in the world of the play.
Lines of verse
<lg> <l>Nor are the duties that thy ſubjects owe,</l> <l>Only compriz’d in this externall ſhow.</l> <l>For harts are heap’d with thofe innumered hoords,</l> <l>That tongues by vttrance cannot vent in words.</l> </lg>
Nor are the duties that thy ſubjects owe,
Only compriz’d in this externall ſhow.
For harts are heap’d with thofe innumered hoords,
That tongues by vttrance cannot vent in words.
Note that titles are often represented differently in other publications. Rather than
reproducing styles that do not conform to our editorial
style manual, make sure to encode truthfully. In other words, do not reproduce
quotation marks that are meant to signify monograph title. Instead,
encode that string of text using the <title> element with a @level value of "m".
Then leave an explanatory note in the encoding. For example, see the
BIBL1.xml entry for MORR2:
<bibl xml:id="MORR2"> <author>Morrison, John</author>. <title level="a">Strype’s Stow: The 1720 Edition of <title level="m">A Survey of London</title></title>. <!-- Note: the title of _A Survey_ appears in quotation marks in the journal. I have not
reproduced this infelicity. -CB --><title level="j">The London Journal</title> 3.1 (1977): 40–54. Web. Subscr. <ref target="http://www.ingentaconnect.com/content/maney/ldn/1977/00000003/00000001/art00003">ingentaconnect</ref>. </bibl>
For a complete list of TEI tags used by MoEML, please consult the MoEML CodeSharing service. In some circumstances MoEML’s schema will not support a TEI element, attribute, and/or value needed to tag a
text type. In these cases, contact Martin Holmes to discuss the issue. It is bad practice to tag text with an incorrect tag to make
in order to make it appear in a certain style.
Use Cascading Style Sheets (CSS) to Tag Text Styles
CSS is a W3C standard used for HTML web pages and in many other contexts too. CSS
is a useful tool for MoEML because its history and vocabulary originate in the print
industry; in its approach and terminology, it embodies the traditions of the printers
and
typesetters of early printed books. At the same time, however, it is a modern web
language
that supports many new textual features of the digital age, such as drop-shadows,
hyperlinks, and cursors.
To tag text style using CSS, use the general-purpose <hi> element and the @style attribute with CSS-specified values. For example,
Any text style written in CSS code will be automatically passed through to the output
web
page. Multiple styling properties can be chained together using semicolons:
Note that, because @style is a global attribute, it can be applied to any XML element (not just the <hi> element). For example, it is possible to apply style to a <p> element using the @style attribute with CSS values:
<p style="margin-left: 4em; text-indent: 1.5em;">The ſpeaker in this Pageant is Edward the third, the laſt Line of his ſpeech is repeated by all the reſt in the Chariot.</p>
Remember that certain TEI elements may already have style properties associated with
them, so the @style element might alter or overwrite these existing style properties when used.
The following CSS properties are most commonly used by MoEML encoders:
"font"
"text"
"display"
"margin"
"padding"
"float"
"height"
"width"
"vertical-align"
Some of the aforementioned properties, such as the "font" or
"text" properties, can be applied at any level of the text, from block levels
such as paragraphs down to inline levels such as individual <hi> tags around a
word. Other properties, however, can only be used at the block level. For instance,
"text-align:center" makes sense for a <p> or a <head>, but not
for a word inside a paragraph.
It is important that encoders do not add extra spaces inside TEI tags. Note the extra
space at the beginning of the <ref> tag in the following example:
the Hall of<ref target="mol:STHE1"> St. Helens Priory</ref>,
This line of XML code claims that the name of the priory begins with a space. It does
not, of course, any more than it includes the trailing comma. Furthermore, should
this code be uploaded to the site, it would output a hyperlink that begins with a
space.
Encode Editorial Notes, Marginal Notes and Labels
We defined editorial notes as notes written by MoEML authors, editors
and contributors. These are encoded using the <note> element, with
@type="editorial". They will be rendered as clickable footnote
numbers in the text which cause a popup to appear containing the note; the
notes themselves are also rendered as a numbered list at the foot of the document.
Use the @resp attribute to assign responsibility for the note using the
person’s @xml:id. Make sure the person’s entry in the personography has an <abbr>
element inside <persName> containing their initials; these initials will then be appended
to the note.1 For example,
<p>...an ingenious Say-Maister,<note type="editorial" resp="mol:JENS1">I.e., assay-master.</note> with his Furnaces...</p>
Note that responsibility for an editorial note can be assigned to more than one person
by supplying multiple @xml:ids in the "value" field of the @resp attribute. For example,
<p>...an ingenious Say-Maister,<note type="editorial" resp="mol:JENS1 mol:MCFI1">I.e., assay-master.</note> with his Furnaces...</p>
Notes and marginal fragments that form part of the original text of a primary source
document
are encoded slightly differently. In many cases, they are not in fact notes at all
but marginal
labels that serve as finding aids for the reader. In this case, encode them using
the <label>
element:
<l>And ſhall I tell ye what that firſt Lord was? <label rendition="#CHRU1_rmlabel" place="margin-right"> <hi style="font-style: italic; font-size: 80%;">Ex <name ref="mol:STOW6">Ioh. Stow</name>.</hi> </label> </l>
Use the @place attribute to specify where the label is in a general sense
("foot", "leftmargin", "rightmargin"), and use the @style
or @rendition attributes to specify its exact dimensions and location
using CSS.
Take the same approach with genuine notes which were part of the original text; here
you can use @type="authorial", and again use @style or @rendition
to set the dimensions of the note.
Encode Words and Phrases in a Language other than English
Mark foreign language strings with the element <foreign> and add the attribute
@xml:lang="XX(X)" where XX(X) is the two- or three-character code for the
language. Note that the content of the <foreign> tag must only contain a text string without mark-up (e.g., no <p>, <title>, or other tags).
MoEML follows the Internet Engineering Task Force guidelines,
whose Language
Subtag Registry is constructed based on the recommendations in BCP 47. In most cases, this means
that where the ISO Standard 639-1 provides a two-letter language code, that code is
used,
but in the absence of a two-letter code, a three-letter code is chosen from ISO 639-2
(this conforms to the current practice outlined in the TEI Guidelines).
For example,
<p>In the Gréeke a Cittie is tearmed <foreign xml:lang="el">ϖόλις</foreign>.</p>
<p>CIties and well peopled places bee called <foreign xml:lang="la">Oppida</foreign>, in Latine...</p>
The following language codes occur frequently in MoEML’s early
modern texts:
Latin: la
Modern Greek (1453–): el
Old English or Anglo-Saxon (ca. 450–1100): ang
Middle English (1100–1500): enm
French: fr
Middle French (ca. 1400–1600): frm
Italian: it
Spanish: es
Encode Special Characters
Some unicode characters that are integral to XML code cannot be used in a text string.
There are only four such characters (i.e., &, <, >, and ") we use in our project. In order to use these special characters in a text string, you must declare them using specific codes as outlined
in the following table. Note that these characters are prohibited by the MoEML Style Guide and therefore should only be used in primary source transcriptions or when otherwise
absolutely necessary. Double quotation marks (") are rendered outwards using a variety of elements (<title> (with @level="a"), <soCalled>, <quote>) and thus should never be used explicitly, other than for demonstration purposes
or primary-source transcriptions. The following table shows the proper encoding of
these characters.
Character
Symbol
Code
Example
Ampersand
&
&
<p>Janelle Jenstad, Kim McLean-Fianer, & Martin Holmes are <title level="m">MoEML</title>’s project directors.</p>
Lesser-than Character
<
<
<p>The cost of a bible in early modern London was < twenty pennies.</p>
Greater-than Character
>
>
<p>The cost of a bible in early modern London was > five pennies.</p>
Straight Quotation Mark
"
"
<p>Tye said <quote>this is how to encode straight quotation marks</quote>.</p>
Encode Non-standard Characters
The TEI Consortium defines non-standard characters as characters not represented in
the published repertoire of available characters [in Unicode] (5. Non-standard Characters and Glyph). Therefore, before encoding a non-standard character, always check to ensure that
the Unicode Consortium has not already published encoding standards for the character.
The set of practices used to encode a non-standard character may be divided into two
parts:
Adding a non-standard character metadata entry to the <teiHeader> of the document in which the non-standard character appears.
Tagging a non-standard character in the <text> of the document and thereby linking the instance of the non-standard character to
the character’s metadata entry in the <teiHeader>.
Declare Non-standard Characters in the <teiHeader>
To encode a non-standard character, nest a <charDecl> element within the <encodingDesc> element in the <teiHeader> of the document. Next, nest a <char> element with an @xml:id attribute inside the <charDecl> element. The value of the @xml:id attribute should begin with the document’s @xml:id followed by an underscore (_) and a simplified representation of the character being
encoded. For example:
Each non-standard character in the document should correspond with an individual <char> element; if there are five non-standard characters in the document, there should
be five individual <char> elements inside the <charDecl> element.
Within the <char> element, nest the following four elements:
<charName>
<desc>
<charProp>
<mapping>
Use the <charName> element to tag the name of the character, borrowing form and terminology from the Unicode character database. For example:
<char> <charName>LATIN SMALL LETTER Y WITH REVERSED HOOK ABOVE</charName> </char>
Use the <desc> element to tag an extended description of the character. Your description should
include the history of the form, variant forms of the glyph, and its relationship
with similar typographical features or characters. For example:
<char> <desc>An abbreviated form of <mentioned>the</mentioned>. This character takes the form of a small latin letter y with a reversed hook above. The closest Unicode character we have to represent this is a small latin letter y with a combining left half ring above. This character appears only twice in the text, which is in black letter gothic.</desc> </char>
Note that, because there is very little published scholarship on early modern non-standard
characters and glyphs, you should consult with the project director or assistant project director before writing an extended description of the character.
The <charProp> element serves as the parent element for both the <localName> and <value> tags. Use the <value> element to tag the non-standard character’s name (i.e., what contemporary typographers
call it). Then use the <localName> element to tag the phrase entity, which indicates that the name of the non-standard character (as tagged by the <value> element) designates an entity. For example:
Use <mapping> elements to tag and label the various forms in which the non-standard character may
appear / has appeared. Each <mapping> element should have a corresponding @type attribute with one of the following values:
Value
Explanation
"standard"
the character as it appears in the document being encoded
"simplified"
the simplified form of the standard character, without accents or ornamentation
"medieval"
the medieval equivalent of the standard character
"modern"
the modern equivalent of the standard character
The following series of <mapping> elements serves as an example:
Combined, the code for a non-standard character (<char>) entry looks like this:
<encodingDesc> <charDecl> <char xml:id="DIXI2_ye"> <charName>LATIN SMALL LETTER Y WITH REVERSED HOOK ABOVE</charName> <desc>An abbreviated form of <mentioned>the</mentioned>. This character takes the form of a small latin letter y with a reversed hook above. The closest Unicode character we have to represent this is a small latin letter y with a combining left half ring above. This character appears only twice in the text, which is in black letter gothic.</desc> <charProp> <localName>entity</localName> <value>yesup</value> </charProp> <mapping type="standard">y͑</mapping> <mapping type="simplified">ye</mapping> <mapping type="medieval">þe</mapping> <mapping type="modern">the</mapping> </char> </charDecl> </encodingDesc>
Tag Non-standard Characters in the <text>
Use the <g> element to tag the non-standard character in the document text. Add a @ref attribute to the <g> element pointing to the @xml:id of the character, as defined by the <char> element in the <teiHeader>. For example:
<g ref="mol:DIXI2_ye">y͑</g>
In some cases, a non-standard character functions as an abbreviation (e.g., characters
inolving a breve [˘]). Markup such instances using the <g> element as described above, yet also include the <choice> and <abbr> elements per the instructions for encoding abbreviations. For example:
To tag a roman numeral, use the <num> element with a @type value of "roman" and a @value attribute pointing to the arabic equivalent of the tagged roman numeral. For example:
Henry <num type="roman" value="8">VIII</num>
Use the <rendition> Element and @rendition Attribute
The previous section outlined how to use the @style attribute and CSS languagge to produce isolated instances of style properties. Some
documents, however, require frequent repetition and standardization of style properties.
In a long work like A Survey of London, marginal notes and labels tend to appear the same way throughout the volume. It
is not practical to describe the font, placement, and font weight over and over.
We can describe the properties of a marginal label (for example) once in the teiHeader,
and refer back to this description in our tagging of individual marginal labels. This
section therefore outlines how to use the <rendition> element and @rendition attribute to write, use, and reuse sets of style properties.
If it does not already exist, add a <tagsDecl> element inside the <encodingDesc> element in the header of the file.
Inside <tagsDecl> element, add a <rendition> element. Add to the <rendition> element both a @scheme attribute with a value of "css" as well as an @xml:id attribute with a unique value. The @xml:id value should consist of the document name followed by an underscore (_) and a descriptor.
The first <rendition> element of METR1.xml serves as an example:
Inside the <rendition> element, add a text string that defines a set of CSS style properties. For example,
the first <rendition> element of METR1.xml defines the style properties for marginal labels:
Use the @rendition attribute within the <body> of your document to reference and apply a particular set of style rules. Each set
of style rules can be referenced by using its @xml:id as the value for the @rendition attribute. For example, suppose that you wanted to apply the set of style rules for
a header as defined in the previous sample; you would do so as follows:
<fw rendition="#SAMP1_head" type="header">Insert text of the header here.</fw>
Encode a Table
A table may be nested inside most elements in a born-digital document. To encode a
table, use the <table> element with the @rows and @cols attributes. The value of the @rows attribute specifies how many rows are in the table you are encoding. Likewise, the
value of the @cols attribute specifies how many columns are in the table you are encoding. For example,
a table with five rows and two columns would be encoded thus:
<table rows="5" cols="2"> <!-- [...] --> </table>
Next, nest <row> elements inside the <table> element. The number of <row> elements should correspond with the number of rows in your table (specified by the
@row attribute attached to the <table> element). Each <row> element should have a @role attribute with a value of either "label" or "data". Use the @role value of "label" to indicate that a row functions as a header (i.e., that its contents do not function
as data but rather as descriptive labels of the data in other rows). Normally, the
first row of a table will function as a header, so the first <row> element nested in a <table> element will have a @role value of "label". For example, a table with five rows, the first of which is a header, and two columns
would be encoded thus:
Finally, nest <cell> elements inside each <row> element. The number of cell elements should correspond with the number of columns
in the table (specified by the @cols attribute attached to the <table> element). Therefore, if a table has two columns, there should be two <cell> elements inside each <row> element. Like the <row> element, each <cell> element must also have a @role attribute with a value of either "data" or "label". Generally speaking, the @role value for a <cell> element should always match the @role value of its parent element. For example, a table with five rows, the first of which
is a header, and two columns would be further encoded thus:
Insert text content inside each <cell> element. You may markup the text content of each <cell> using most xml tags, such as <ref> and <name>. The text content will render in table form in accordance with the code structure
inside the <table> element. You may also nest a <head> element above the first <row> element. Use the <head> element to tag a text string that functions as a title or other description for your
table. Consider the following table:
Label A
Label B
Data Point 1A
Data Point 1B
Data Point 2A
Data Point 2B
Data Point 3A
Data Point 3B
Data Point 3A
Data Point 3B
Example Table
This table has been encoded thus:
<table rows="5" cols="2"> <head>Example Table</head> <row role="label"> <cell role="label">Label A</cell> <cell role="label">Label B</cell> </row> <row role="data"> <cell role="data">Data Point 1A</cell> <cell role="data">Data Point 1B</cell> </row> <row role="data"> <cell role="data">Data Point 2A</cell> <cell role="data">Data Point 2B</cell> </row> <row role="data"> <cell role="data">Data Point 3A</cell> <cell role="data">Data Point 3B</cell> </row> <row role="data"> <cell role="data">Data Point 3A</cell> <cell role="data">Data Point 3B</cell> </row> </table>
Note that MoEML’s style sheet does not support more complex tables at this time (e.g., tables with
vertical header labels or tables with vertical and horizontal header labels). In most
instances, you should be able to display data in a simple table form with a single
row of header labels. If you must display data in a more complex table form, consult
with the project’s lead programmer.
Use Split Tags to Represent Overlapping Hierarchies
Occasionally, it may be necessary to split an interrupted referring string
into two or more tags. For example, it is possible for a page break, along with running
headers or footers, to interrupt a <name> tag in a transcribed text, as follows
(encoding simplified here from TRIU2.xml):
[...]Margaret, eldeſt
daughter to king <name ref="mol:HENR5" xml:id="TRIU2_HENR5_1" next="#TRIU2_HENR5_2">Henrie</name><lb/><fw type="catchword" style="float: right;">the</fw><pb/><fw type="header">re-vnited Britannia</fw><name ref="mol:HENR5" prev="#TRIU2_HENR5_1" xml:id="TRIU2_HENR5_2"><hi style="font-style: italic;">the ſeauenth</hi></name>, to Iames the fourth king of
Scotland[...].
Here, the name Henrie the ſeauenth is
divided by the formwork and page break encoding. To include the formwork and page
break
information as part of the <name> tag would be untruthful, so the tag must be
split. However, to tag Henrie and the
ſeauenth as two <name> tags would be equally misleading since it
erroneously suggests that each name part is actually a separate mention. The solution
shown above is to assign each <name> tag an @xml:id in order to link them
with the @next and @prev attributes, which indicate that the two
separate tags are related.
In each <name> tag, add an @xml:id attribute with a value that
follows the following formula: [xml:id of document]_[xml:id of person
mentioned]_[lowest possible unique integer (i.e. unique to the document)].
Then, add a @next attribute to the
first <name> with a value that uses a pound sign (#) to point to the
@xml:id of the second (next) <name> element. Finally, add a
@prev attribute to the second <name> element with a value that
points to the first (previous) <name> element. These attributes link the two
separate tags as one.
Note that there is no reason to use split tags when a reference occurs across a line
break, because a single <ref> tag can contain one or more self-closing <lb> element(s).
Index Praxis Documentation
When adding new documentation to praxis, always encode a list of index terms associated
with the new documentation. To do this, insert an <index> element below the heading (<head>) for each new <div>. Add an @indexName attribute with a value of "documentation_manual" to the <index> element. Nest a series of terms tagged with the <term> element inside the <index> element. For example,
Your list of index terms should be consistent with terms already used in the index,
although it will likely be necessary to use new terms as well. All new terms should
be lowercase and plural.
MoEML’s v.6 website now displays interesting snippets on its homepage. Interesting snippets are short one- or two-sentence passages from MoEML library texts or encyclopedia articles that are in some way provocative, compelling,
or humorous. Should you come across such a passage in your work as a MoEML encoder, we encourage you to tag it using the <seg> element with a @type value of "interestingSnippet" and a unique @xml:id. The following interesting snippet from The Shoemaker’s Holiday by Thomas Dekker (SHOE1.xml) serves as an example:
<seg type="interestingSnippet" xml:id="SHOE2_argument">The argument of the play I will set down in this epistle: Sir Hugh Lacy, Earl of Lincoln, had a young gentleman of his own name, his near kinsman, that loved the Lord Mayor’s daughter of London;</seg>
Note that the @xml:id should be the document’s @xml:id followed by an underscore (_) and a unique descriptor. Moreover, the text string
inside the <seg> tag must be under 400 characters and be contained by a single block-level element
such as a <p>.
Add the MoEML Decorative Daisy as a Block Element
It is possible to add the MoEML decorative daisy as a block element in between paragraphs as follows:
<figure type="decorativeFlower"></figure>
Note that we should be judicious in our use of the decorative daisy (i.e., only use
it in born-digital, front-end pages). When in doubt, consult Kim McLean-Fiander for advice.
Landels-Gruenewald, Tye, Martin D. Holmes, and Cameron Butt. General Encoding Practices.The Map of Early Modern London, edited by Janelle Jenstad, U of Victoria, 20 Jun. 2018, mapoflondon.uvic.ca/encoding_practices.htm.
Chicago citation
Landels-Gruenewald, Tye, Martin D. Holmes, and Cameron Butt. General Encoding Practices.The Map of Early Modern London. Ed. Janelle Jenstad. Victoria: University of Victoria. Accessed June 20, 2018. http://mapoflondon.uvic.ca/encoding_practices.htm.
APA citation
Landels-Gruenewald, T., Holmes, M. D., & Butt, C. 2018. General Encoding Practices. In J. Jenstad (Ed), The Map of Early Modern London. Victoria: University of Victoria. Retrieved from http://mapoflondon.uvic.ca/encoding_practices.htm.
RIS file (for RefMan, EndNote etc.)
Provider: University of Victoria
Database: The Map of Early Modern London
Content: text/plain; charset="utf-8"
TY - ELEC
A1 - Landels-Gruenewald, Tye
A1 - Holmes, Martin
A1 - Butt, Cameron
ED - Jenstad, Janelle
T1 - General Encoding Practices
T2 - The Map of Early Modern London
PY - 2018
DA - 2018/06/20
CY - Victoria
PB - University of Victoria
LA - English
UR - http://mapoflondon.uvic.ca/encoding_practices.htm
UR - http://mapoflondon.uvic.ca/xml/standalone/encoding_practices.xml
ER -
RefWorks
RT Web Page
SR Electronic(1)
A1 Landels-Gruenewald, Tye
A1 Holmes, Martin
A1 Butt, Cameron
A6 Jenstad, Janelle
T1 General Encoding Practices
T2 The Map of Early Modern London
WP 2018
FD 2018/06/20
RD 2018/06/20
PP Victoria
PB University of Victoria
LA English
OL English
LK http://mapoflondon.uvic.ca/encoding_practices.htm
TEI citation
<bibl type="mla"><author><name ref="#LAND2"><surname>Landels-Gruenewald</surname>,
<forename>Tye</forename></name></author>, <author><name ref="#HOLM3"><forename>Martin</forename>
<forename>D.</forename> <surname>Holmes</surname></name></author>, and <author><name
ref="#BUTT1"><forename>Cameron</forename> <surname>Butt</surname></name></author>.
<title level="a">General Encoding Practices</title>. <title level="m">The Map of Early
Modern London</title>, edited by <editor><name ref="#JENS1"><forename>Janelle</forename>
<surname>Jenstad</surname></name></editor>, <publisher>U of Victoria</publisher>,
<date when="2018-06-20">20 Jun. 2018</date>, <ref target="http://mapoflondon.uvic.ca/encoding_practices.htm">mapoflondon.uvic.ca/encoding_practices.htm</ref>.</bibl>
Encoder, research assistant, and copy editor, 2012–13. Cameron completed his undergraduate
honours degree in English at the University of Victoria in 2013. He minored in French
and has a keen interest in Shakespeare, film, media studies, popular culture, and
the geohumanities.
Janelle Jenstad, associate professor in the department of English at the University
of Victoria, is the general editor and coordinator of The Map of Early Modern London. She is also the assistant coordinating editor of Internet Shakespeare Editions. She has taught at Queen’s University, the Summer Academy at the Stratford Festival,
the University of Windsor, and the University of Victoria. Her articles have appeared
in the Journal of Medieval and Early Modern Studies, Early Modern Literary Studies, Elizabethan Theatre, Shakespeare Bulletin: A Journal of Performance Criticism, and The Silver Society Journal. Her book chapters have appeared (or will appear) in Performing Maternity in Early Modern England (Ashgate, 2007), Approaches to Teaching Othello (Modern Language Association, 2005), Shakespeare, Language and the Stage, The Fifth Wall: Approaches to Shakespeare from
Criticism, Performance and Theatre Studies (Arden/Thomson Learning, 2005), Institutional Culture in Early Modern Society (Brill, 2004), New Directions in the Geohumanities: Art, Text, and History at the Edge of Place (Routledge, 2011), and Teaching Early Modern English Literature from the Archives (MLA, forthcoming). She is currently working on an edition of The Merchant of Venice for ISE and Broadview P. She lectures regularly on London studies, digital humanities, and
on Shakespeare in performance.
Research assistant, 2013-15, and data manager, 2015 to present. Tye completed his
undergraduate honours degree in English at the University of Victoria in 2015.
Director of Pedagogy and Outreach, 2015–present; Associate Project Director, 2015–present;
Assistant Project Director, 2013-2014; MoEML Research Fellow, 2013. Kim McLean-Fiander
comes to The Map of Early Modern London from the Cultures of Knowledge digital humanities project at the University of Oxford, where she was the editor of Early Modern Letters Online, an open-access union catalogue and editorial interface for correspondence from the
sixteenth to eighteenth centuries. She is currently Co-Director of a sister project
to EMLO called Women’s Early Modern Letters Online (WEMLO). In the past, she held an internship with the curator of manuscripts at the Folger Shakespeare Library, completed a doctorate at Oxford on paratext and early modern women writers, and worked a number of years for the
Bodleian Libraries and as a freelance editor. She has a passion for rare books and manuscripts as social
and material artifacts, and is interested in the development of digital resources
that will improve access to these materials while ensuring their ongoing preservation
and conservation. An avid traveler, Kim has always loved both London and maps, and
so is particularly delighted to be able to bring her early modern scholarly expertise
to bear on the MoEML project.
Programmer, 2018-present; Junior Programmer, 2015 to 2017; Research Assistant, 2014
to 2017. Joey Takeda is an MA student at the University of British Columbia in the
Department of English (Science and Technology research stream). He completed his BA
honours in English (with a minor in Women’s Studies) at the University of Victoria
in 2016. His primary research interests include diasporic and indigenous Canadian
and American literature, critical theory, cultural studies, and the digital humanities.
Programmer at the University of Victoria Humanities Computing and Media Centre (HCMC).
Martin ported the MOL project from its original PHP incarnation to a pure eXist database
implementation in the fall of 2011. Since then, he has been lead programmer on the
project and has also been responsible for maintaining the project schemas. He was
a co-applicant on MoEML’s 2012 SSHRC Insight Grant.