Martin Holmes, Lead Programmer on MoEML, is deeply committed to open-access projects and open documentation of those projects.
He has led the way in making MoEML’s documentation and tagging freely available in a variety of XML forms (including
TEI Lite XML). His CodeSharing Service takes open documentation to a new level. Now, MoEML users can search our complete project and see every instance of every TEI element,
attribute, and value that we have added to MoEML texts. He presented a formal paper at the TEI Conference at Northwestern University in October 2014. With his permission, we share the complete abstract of this paper here (republished from the TEI 2014 site and lightly edited). His paper concludes with an invitation to comment on the tool.
We hope that many other projects will adopt this tool, thus making visible the usually
invisible labour and critical decisions entailed in tagging. (JJ)
Introduction
Although the TEI Guidelines are full of helpful examples, and other initiatives such
as TEI By Example have made great progress in providing more access to samples of text-encoding to
help beginners get started, there is no doubt that one of the biggest obstacles to
encoders at many levels is finding out how other scholars and projects have chosen
to encode a particular feature or use a specific tag or attribute. Burghart and Rehbein tell us that the majority of TEI users are self-taught or learned by doing, and Dee (2014) reports that users need a source for a compendium of examples suitable for inductive learning. Many projects now share their XML code, but that in itself is only marginally helpful.
It can take substantial time to sift through the XML code in a large project to find
what you’re looking for.
This talk presents a simple specification for an Application Programming Interface, along with a sample implementation written in XQuery and designed for the eXist XML database, providing straightforward access both for applications and end-users to sample code
from any TEI project. The API is modelled on the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH), a mechanism designed to allow archival search tools to ingest metadata
from repositories. The CodeSharing protocol and the sample implementation were first
presented at the >Digital.Humanities@Oxford Summer School in July 2013, and a number of improvements have been made to the code and specification based
on feedback from that presentation.
Target audience
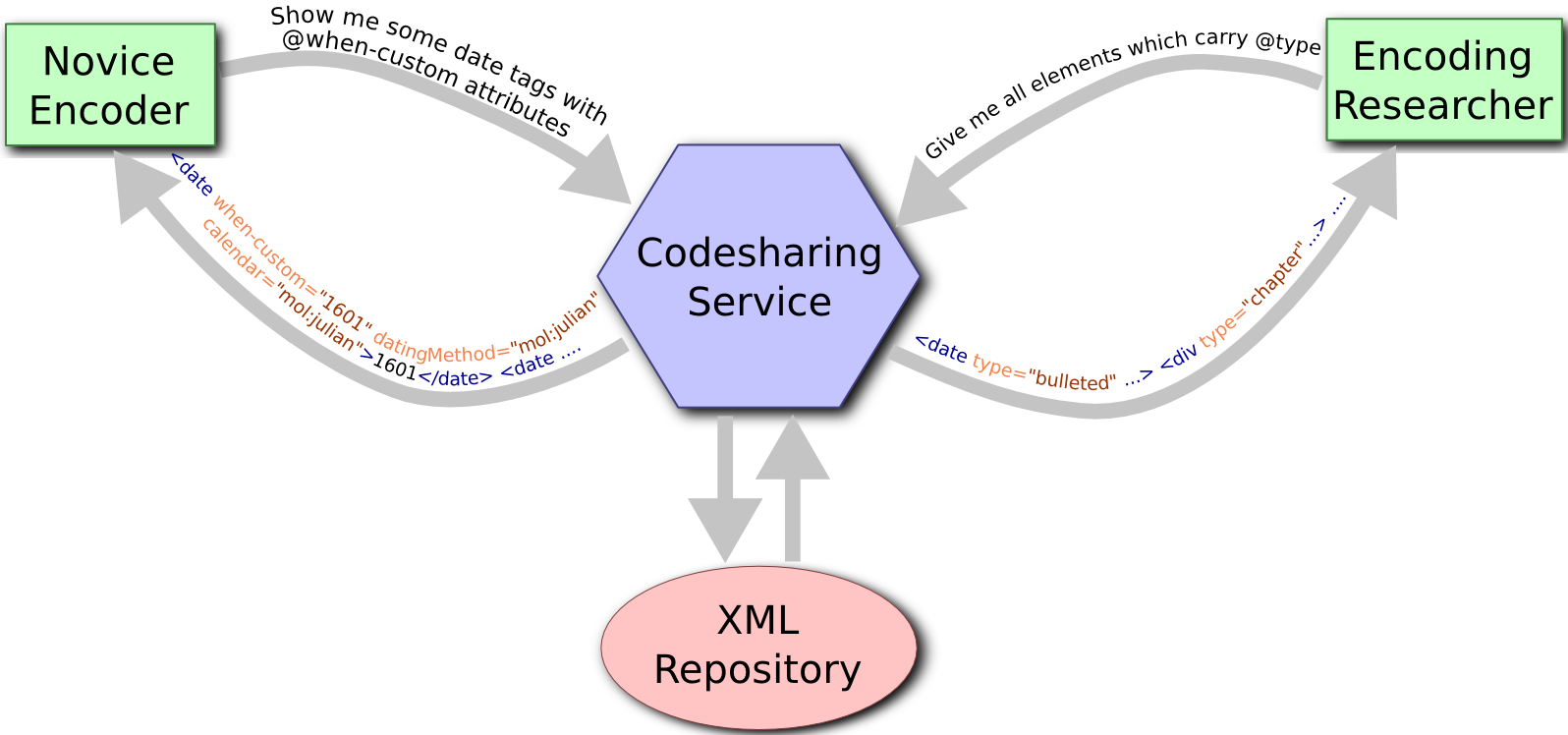
The CodeSharing proposal arises out of two separate but intersecting needs: those
of novice encoders and project managers who are not really TEI experts, and those
of people doing research into encoding practices on a large scale across multiple
projects.
Novice encoders
At the time of writing, The Map of Early Modern London (MoEML) project, a typical grant-supported digital humanities project1 with a large encoding component, has a team of around seven or eight encoders working
part-time, with frequent changes of personnel. The project provides regular TEI training,
but there is usually a mix of experienced and rookie encoders, and project managers
have to provide a lot of live help to supplement the documentation. One of the most
difficult things for inexperienced encoders is to find examples of the usage of elements
and attributes they haven’t used before. There are of course lots of resources to
help with this, including the TEI Guidelines examples, the TEI by Example project, and Marjorie Burghart’s Cheatsheets, but it is unusual to find in such external resources enough examples of the use
of a particular element or attribute which exactly match the current use-case. It
is really more effective to search the codebase of your own project.
The MoEML encoders do have access to a lot of the existing codebase, but doing text searches
of this is often ineffective. They are not normally familiar with XPath, XQuery, or regular expressions, and most will never learn them, so in searching for e.g. a <birth> element which has a @notBefore-custom attribute, they will search for <birth notBefore-custom, and therefore miss all the <birth> elements which happen to have their @datingMethod attribute first, or which have two spaces between the tag name and the attribute
name instead of one. Searching the entire codebase may also retrieve examples of encoding
in obsolete or unedited documents, which might provide bad examples. It is more effective,
therefore, to enable them to search the online XML database which contains only documents
which have actually been published.
To serve these needs, we began to think about writing a simple search interface which
would form part of our MoEML web application, and which would provide access to lots of examples of individual
tags and attributes.
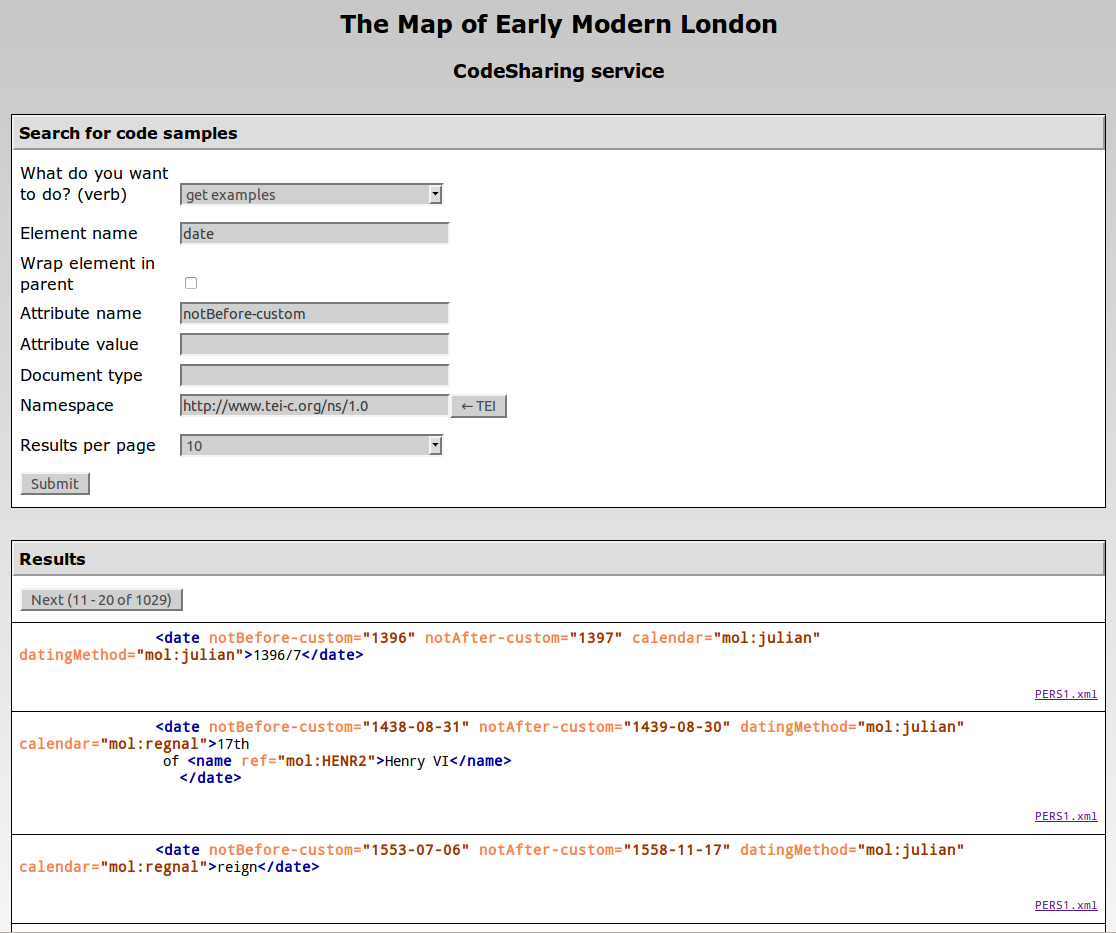
The Web interface of the CodeSharing service on the MoEML site.
This straightforward form-based interface enables our encoders to retrieve examples
of encoding quickly and easily from across our text collection.
Research into Encoding Practices
As I worked on the interface above, I also began to think about broader possibilities.
In our work on the TEI Council, we frequently find ourselves asking:
Do people ever actually use this element or attribute?
If so, how do they use it?
We typically resort to posting questions to the TEI-L mailing list to ask for examples from the community, but this is a rather slow, hit-and-miss method
of gathering data. If we could retrieve large numbers of sample usages of particular elements or attributes
and analyse them, this would be very helpful in development of the Guidelines, and in assessing the impact of any change we might make to the schemas or recommendations.
We might also be able to supply fresh examples for the Guidelines text itself by selecting from among thousands of sample usages, rather than drawing
only from our own projects or concocting examples. It would therefore be very helpful
if there were an API that projects could implement to provide access to samples of
their encoding practice in a standardized way, such that the same query could be run
over multiple projects simultaneously and the results combined.
A CodeSharing service can serve the needs of novice encoders as well as encoding researchers.
The Model: OAI-PMH
To answer these needs, I designed a web service that could be provided by large- and
medium-scale encoding projects, enabling anyone to gather examples of their encoding
practice directly from their data. I modelled my protocol on an existing, well-tested
system: the Open Archives Initiative Protocol for Metadata Harvesting, or OAI-PMH, which I had previously implemented for another project.
OAI-PMH is commendably simple and well designed. A participating repository may be
a data provider, which exposes structured metadata through a web service implementing
the OAI-PMH API; or a service provider, which gathers that metadata through requests
to the data providers. The service providers can then act as meta-repositories, or
federated archives, providing search functionality that encompasses the collections
of all the data providers who have exposed their metadata for harvesting. An example
is OCLC’s WorldCat, which aggregates data from a large number of repositories and makes them searchable
from a single interface. The OAI-PMH API is based on HTTP requests using GET or POST. It is designed to allow a harvester to find out what kinds of resources a repository
has, and to gather full metadata records. All responses are in XML, and conform to a standard schema.
OAI-PMH is based around six core verbs:
Identify
ListMetadataFormats
ListIdentifiers
ListSets
ListRecords
GetRecord
A request like this one (made to the OAI-PMH interface provided by the Colonial Correspondence of BC and Vancouver Island project, at http://bcgenesis.uvic.ca):
http://bcgenesis.uvic.ca/oai.xq?verb=Identify
will result in a response in XML which provides identifying information about the
repository:
<OAI-PMH xmlns="http://www.openarchives.org/OAI/2.0/" xsi:schemaLocation="http://www.openarchives.org/OAI/2.0/ http://www.openarchives.org/OAI/2.0/OAI-PMH.xsd"> <responseDate>2013-05-08T18:09:31.047Z</responseDate> <request verb="Identify">http://bcgenesis.uvic.ca/oai.xq</request> <Identify> <repositoryName>The colonial despatches of Vancouver Island and British Columbia 1846-1871</repositoryName> <baseURL>http://bcgenesis.uvic.ca/oai.xq</baseURL> <protocolVersion>2.0</protocolVersion> <adminEmail>mholmes@uvic.ca</adminEmail> <adminEmail>cpetter@uvic.ca</adminEmail> <earliestDatestamp>2012-11-19T12:00:00Z</earliestDatestamp> <deletedRecord>no</deletedRecord> <granularity>YYYY-MM-DD</granularity> <description> <oai-identifier xmlns="http://www.openarchives.org/OAI/2.0/oai-identifier" xsi:schemaLocation="http://www.openarchives.org/OAI/2.0/oai-identifier http://www.openarchives.org/OAI/2.0/oai-identifier.xsd"> <scheme>oai</scheme> <repositoryIdentifier>bcgenesis.uvic.ca</repositoryIdentifier> <delimiter>:</delimiter> <sampleIdentifier>oai:bcgenesis.uvic.ca:B63030SP.scx</sampleIdentifier> </oai-identifier> </description> </Identify> </OAI-PMH>
The harvester can use the ListRecords verb to retrieve individual records, which are typically in the form of Dublin Core elements embedded in a larger structure in the OAI namespace:
<record xmlns="http://www.openarchives.org/OAI/2.0/"> <header> <identifier>oai:bcgenesis.uvic.ca:B585TE13.scx</identifier> <datestamp>2013-12-17T14:29:44.553-08:00</datestamp> <setSpec>1858</setSpec> <setSpec>publicOffices</setSpec> <setSpec>B.C.</setSpec> </header> <metadata> <dc xmlns="http://www.openarchives.org/OAI/2.0/oai_dc/" xsi:schemaLocation="http://www.openarchives.org/OAI/2.0/oai_dc/ http://www.openarchives.org/OAI/2.0/oai_dc.xsd"> <title xmlns="http://purl.org/dc/elements/1.1/">The colonial despatches of Vancouver Island and British Columbia 1846-1871: 11566, CO 60/2, p. 291; received 13 November. Trevelyan to Merivale (Permanent Under-Secretary)</title> <date xmlns="http://purl.org/dc/elements/1.1/">1858-11-12</date> [...] </dc> </metadata> </record>
Most repositories will have thousands of records, and retrieving them all at once
would place an unacceptable burden on the server and network infrastructure, so OAI-PMH
has a built-in staging system. Records are supplied in batches, and each batch ends
with a resumption token which acts as a flow-control device:
The format of the resumption token is not defined by the specification; the data provider
may use any suitable format, and the harvester simply has to echo it back to the data
provider to get the next set of records. This gives the data provider complete control
over how rapidly it provides the data, and even in the course of a large transfer,
the provider can throttle or accelerate its provision of records in response to local
conditions such as server load or network bandwidth.
The CodeSharing Service
The complete specification for the CodeSharing API is available at http://mapoflondon.uvic.ca/codesharing_protocol.xhtml, as part of the sample implementation on the MoEML site; in what follows I cover only some key aspects of it.
The Request API
CodeSharing is an XML-based API provided over HTTP, just like OAI-PMH. On the model
of OAI-PMH, it’s also based on a verb parameter, with five possible values:
identify
listElements
listAttributes
listNamespaces
getExamples
The first four are designed to discover the nature of the repository, and what elements,
attributes, and namespaces occur in its document collections. The final value is a
request for actual example encodings; when that value is used, other key-value pairs
provide details about what has been requested:
elementName
attributeName
attributeValue
Each parameter is used to specify what examples are being requested. These can obviously
be combined, so a request for:
elementName=hi&attributeName=rend
will retrieve only hi elements which have @rend attributes;
attributeName=rend&value=italic
will retrieve any elements which have @rend="italic".
Two further parameters are available:
namespace (the namespace for requested elements, defaulting to the TEI namespace)
wrapped (whether or not to return the parent containing the target element)
So a request for:
elementName=hi&wrapped=true
will retrieve <hi> elements in the context of their parent element. Encoders find it helpful to see
not just the target element, but the surrounding context too.
Finally, we have to consider flow control, as in the case of OAI-PMH. It would be
disastrous to attempt to honour a request for all of the <TEI> elements in a large collection; we need to negotiate a reasonable chunk size for
the harvester and the server. In the case of OAI-PMH, the data provider always dictates
the number of records it is prepared to supply. In the case of CodeSharing, I wanted
to allow a little more flexibility, so there is a further parameter the harvester
can provide:
maxItemsPerPage (a positive integer)
The provider service is not required to honour this request; it may decide to send
fewer items. But it may be sensitive enough to know, for instance, that when the request
is for a relatively small element such as <hi>, it might be practical to send 100 examples in one response, whereas it might send
only 20 in the case of requests for <p> or <div> elements.
The Response
What form should the server’s response take? The obvious answer is that it should
be XML, and in fact that it should be TEI P5 XML. The exact format of the response
document is only loosely specified, although some parts of it must follow certain
rules. If the value of the verb parameter is listElements, for instance, then the body of the document must contain the list of all elements
appearing in the collection as a list:
Similar structures are used to list attributes and namespaces.
For returning actual examples, CodeSharing makes use of the <egXML> element,
which is also used for example code in the TEI Guidelines. The <egXML> element is in its own special namespace, http://www.tei-c.org/ns/Examples, and all the elements that are children of it, in the example code, are also by default
in that namespace. This is useful, because it means that we can easily distinguish
example code from other parts of the TEI file. (It also means we can use the API to
retrieve examples of code which themselves are intended as examples in their original context.)
In addition to the results of the query, the protocol specification also requires
that the parameters of the original request be returned to the requestor; this means
that the result document is a complete and self-contained record of the query and
results. Full details are available in the protocol documentation.
A Sample Implementation
A sample implementation of the CodeSharing protocol, including an HTML front-end,
as shown in Figure 1, is available at http://mapoflondon.uvic.ca/codesharing.htm. It is written in XQuery 3.0 and runs in the eXist XML database which hosts the MoEML web application. The open-source code is available on SourceForge at https://sourceforge.net/projects/codesharing/, and includes these files:
codesharing.xql (the XQuery implementation providing responses to queries in XML)
codesharing_config.xql (a simple settings file that tailors the service to your own project)
codesharing.xsl (a transformation which produces the HTML search page you see on the MoEML site)
codesharing_protocol.xhtml (a semi-formal description of the API)
codesharing.odd (an ODD file from which a schema can be generated to validate CodeSharing API responses)
I would welcome any contributions in the form of improvements, suggestions, and implementations
in other languages.
Burghart, Marjorie, and Malte Rehbein. The Present and Future of the TEI Community for Manuscript Encoding.Journal of the Text Encoding Initiative 2 (2012): n.pag. TEI. Open.. doi:10.4000/jtei.372.
Holmes, Martin D.CodeSharing:
A Simple API for Disseminating
our TEI Encoding.The Map of Early Modern London, edited by Janelle Jenstad, U of Victoria, 20 Jun. 2018, mapoflondon.uvic.ca/BLOG10.htm.
Chicago citation
Holmes, Martin D.CodeSharing:
A Simple API for Disseminating
our TEI Encoding.The Map of Early Modern London. Ed. Janelle Jenstad. Victoria: University of Victoria. Accessed June 20, 2018. http://mapoflondon.uvic.ca/BLOG10.htm.
APA citation
Holmes, M. D. 2018. CodeSharing:
A Simple API for Disseminating
our TEI Encoding. In J. Jenstad (Ed), The Map of Early Modern London. Victoria: University of Victoria. Retrieved from http://mapoflondon.uvic.ca/BLOG10.htm.
RIS file (for RefMan, EndNote etc.)
Provider: University of Victoria
Database: The Map of Early Modern London
Content: text/plain; charset="utf-8"
TY - ELEC
A1 - Holmes, Martin
ED - Jenstad, Janelle
T1 - CodeSharing:
A Simple API for Disseminating
our TEI Encoding
T2 - The Map of Early Modern London
PY - 2018
DA - 2018/06/20
CY - Victoria
PB - University of Victoria
LA - English
UR - http://mapoflondon.uvic.ca/BLOG10.htm
UR - http://mapoflondon.uvic.ca/xml/standalone/BLOG10.xml
ER -
RefWorks
RT Web Page
SR Electronic(1)
A1 Holmes, Martin
A6 Jenstad, Janelle
T1 CodeSharing:
A Simple API for Disseminating
our TEI Encoding
T2 The Map of Early Modern London
WP 2018
FD 2018/06/20
RD 2018/06/20
PP Victoria
PB University of Victoria
LA English
OL English
LK http://mapoflondon.uvic.ca/BLOG10.htm
TEI citation
<bibl type="mla"><author><name ref="#HOLM3"><surname>Holmes</surname>, <forename>Martin</forename>
<forename>D.</forename></name></author> <title level="a">CodeSharing:
A Simple API for Disseminating
our TEI Encoding</title>. <title level="m">The Map of Early Modern London</title>,
edited by <editor><name ref="#JENS1"><forename>Janelle</forename> <surname>Jenstad</surname></name></editor>,
<publisher>U of Victoria</publisher>, <date when="2018-06-20">20 Jun. 2018</date>,
<ref target="http://mapoflondon.uvic.ca/BLOG10.htm">mapoflondon.uvic.ca/BLOG10.htm</ref>.</bibl>
Janelle Jenstad, associate professor in the department of English at the University
of Victoria, is the general editor and coordinator of The Map of Early Modern London. She is also the assistant coordinating editor of Internet Shakespeare Editions. She has taught at Queen’s University, the Summer Academy at the Stratford Festival,
the University of Windsor, and the University of Victoria. Her articles have appeared
in the Journal of Medieval and Early Modern Studies, Early Modern Literary Studies, Elizabethan Theatre, Shakespeare Bulletin: A Journal of Performance Criticism, and The Silver Society Journal. Her book chapters have appeared (or will appear) in Performing Maternity in Early Modern England (Ashgate, 2007), Approaches to Teaching Othello (Modern Language Association, 2005), Shakespeare, Language and the Stage, The Fifth Wall: Approaches to Shakespeare from
Criticism, Performance and Theatre Studies (Arden/Thomson Learning, 2005), Institutional Culture in Early Modern Society (Brill, 2004), New Directions in the Geohumanities: Art, Text, and History at the Edge of Place (Routledge, 2011), and Teaching Early Modern English Literature from the Archives (MLA, forthcoming). She is currently working on an edition of The Merchant of Venice for ISE and Broadview P. She lectures regularly on London studies, digital humanities, and
on Shakespeare in performance.
Research assistant, 2013-15, and data manager, 2015 to present. Tye completed his
undergraduate honours degree in English at the University of Victoria in 2015.
Director of Pedagogy and Outreach, 2015–present; Associate Project Director, 2015–present;
Assistant Project Director, 2013-2014; MoEML Research Fellow, 2013. Kim McLean-Fiander
comes to The Map of Early Modern London from the Cultures of Knowledge digital humanities project at the University of Oxford, where she was the editor of Early Modern Letters Online, an open-access union catalogue and editorial interface for correspondence from the
sixteenth to eighteenth centuries. She is currently Co-Director of a sister project
to EMLO called Women’s Early Modern Letters Online (WEMLO). In the past, she held an internship with the curator of manuscripts at the Folger Shakespeare Library, completed a doctorate at Oxford on paratext and early modern women writers, and worked a number of years for the
Bodleian Libraries and as a freelance editor. She has a passion for rare books and manuscripts as social
and material artifacts, and is interested in the development of digital resources
that will improve access to these materials while ensuring their ongoing preservation
and conservation. An avid traveler, Kim has always loved both London and maps, and
so is particularly delighted to be able to bring her early modern scholarly expertise
to bear on the MoEML project.
Programmer, 2018-present; Junior Programmer, 2015 to 2017; Research Assistant, 2014
to 2017. Joey Takeda is an MA student at the University of British Columbia in the
Department of English (Science and Technology research stream). He completed his BA
honours in English (with a minor in Women’s Studies) at the University of Victoria
in 2016. His primary research interests include diasporic and indigenous Canadian
and American literature, critical theory, cultural studies, and the digital humanities.
Programmer at the University of Victoria Humanities Computing and Media Centre (HCMC).
Martin ported the MOL project from its original PHP incarnation to a pure eXist database
implementation in the fall of 2011. Since then, he has been lead programmer on the
project and has also been responsible for maintaining the project schemas. He was
a co-applicant on MoEML’s 2012 SSHRC Insight Grant.